7 Tricks to score more in Bio boards exam
We know that boards exams are about to start in around a month’s time and 12th boards is especially more important as this is one of the deciding factors in the career option chosen by you. Marks achieved in 12th boards are considered in majority of competitive exams, so we decided to conduct a webinar to showcase you that how you can score more in boards exams.
The webinar was taken by our Bio expert Miss Anjali Ahuja and as it is clear from heading itself that it is focused majorly on scoring more in Bio. For those of you who missed it and want to see, the video is mentioned below and in case if you are a bit short of time to watch complete webinar then you can go through the blog written below.
In this blog, we will be covering 7 tricks that will help you in scoring more than 90% in upcoming Bio boards exams. There are certain examples of questions from previous year question papers along with the explanation on how to attempt them properly. Of course, we will be covering other subjects as well but for now, let’s concentrate on Biology.
- No need to write everything that you know
Students these days prepare so well that they know approximately everything about all the topics, but get confused at the time of writing it in the exam. Confused to make a decision, that how much to write on a specified topic based on the mark assigned to the question. Question from a particular topic may come for 5 marks, 4 marks, 3 marks or even 2marks but students are not sure that how much they should write under it.
To clarify this, you need to read the question carefully, concentrate on the language and analyse that what exactly is being asked in the question. Students sometimes end up writing too much for just a 2 marks question and end up wasting too much time on it which they need to avoid.
This will not only ensure timely completion of question paper but also give you ample of time to devote to important questions.
- The Experiments
Practice all the experiments because one of them will surely come in the exam. We have taken an example from previous year question paper to explain you the type of question that can come and how to attempt it.

In this you first need to define what is ‘semi-conservative process’ and then further support it by drawing a well labelled diagram. Refer the example below to understand it properly.

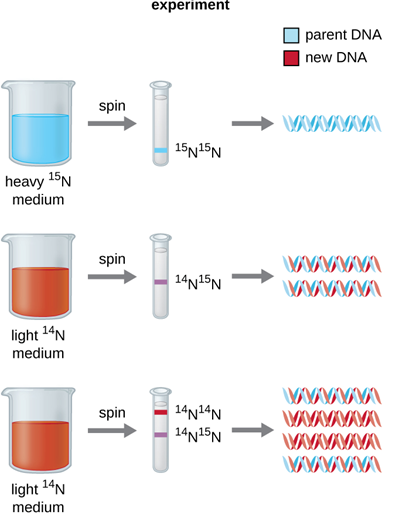

Like you can see that explanation in the diagram is very important to fetch more marks, which indeed is our final objective.
- Diagrams
Diagrams are very important in Biology. A suggestion from our side, don’t assume that if it is not asked in the question then you don’t need to draw the diagram. Draw it wherever you can but avoid spending too much time on it, be wise in your decision making on when to make it and when not considering time constraint. Also, it is very important to practice the diagrams as that way you’ll be easily able to remember it.
Also, there is a very high chance of diagrams from two topics to come in exams: growth curve in ecology and one of the diagrams of the reproductive system. Now, below is an example of a question from past question papers and our tips on attempting it.

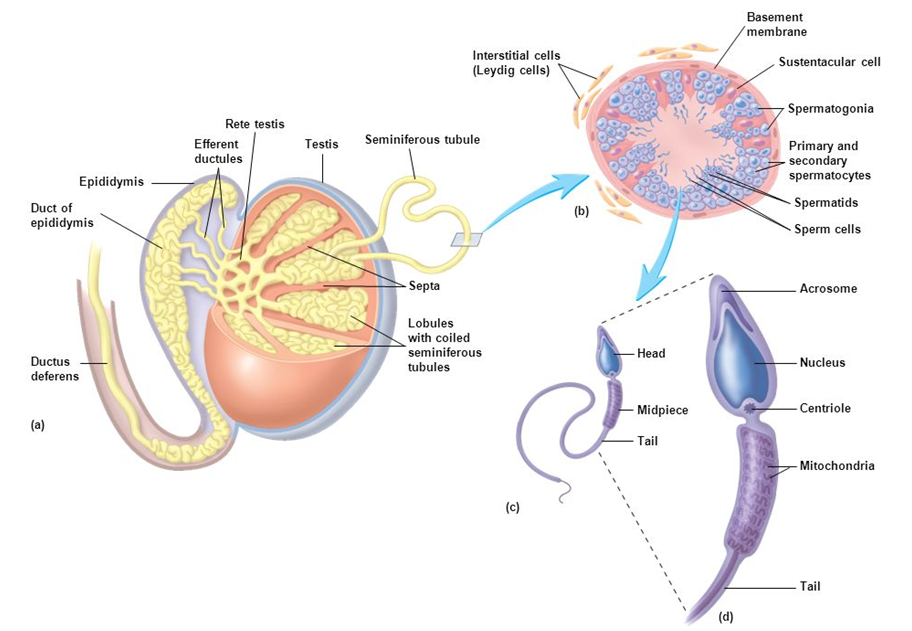
The explanation is as follows:


Like you can see in above example, location and function both are being explained. The explanation though is short but contains enough information to fetch you good marks.
  4.Illustration of answers
Illustration or presentation of answers is very important. Students often face confusion regarding what exactly to write. To clear this confusion I’ll say that you need to write as per the mark of the question and then further explain it through the diagram. This type of presentation is enough to fetch 5 marks for a 2 marks question thus avoiding any opportunity for the examiner to deduct marks.
Carefully observe the mentioned example to understand it further.

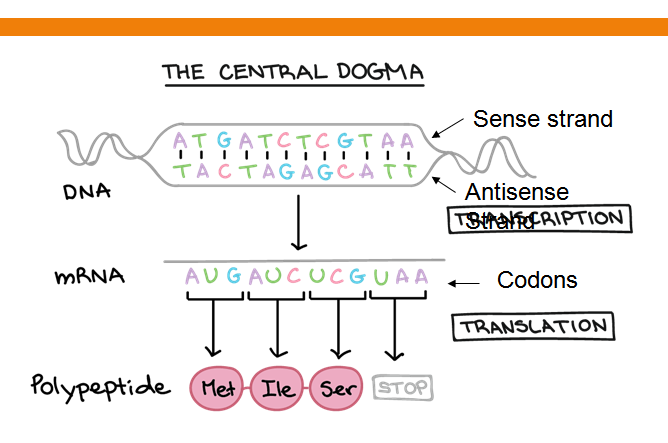
Like it, you can see that the answer isn’t too long but is well supported by the diagram. This will fetch you full marks for a 2 mark question.
  5.Dealing with ‘Ecology’ question
Ecology is a very interesting topic which can fetch you more marks or fewer marks than expected. In this topic, you should give a real-life example for every explanation. The examples can be of any recent flood, earthquake, forest fire etc.
There should be ample of use of facts in your answer. And try to use as many technical terms as possible such as afforestation, deforestation, etc.
Now let me show you my an example that how you can attempt questions on ecology by an example.

  6. Important questions
In this point, I will be talking about some important topics from which questions are most likely to come. These topics are determined by close analysis of pattern past few years question papers.
- Plasmodium life cycle
- Reproductive health
- Contraceptive devices
- Ecological succession
- Reverse transcription about HIV
- Ecological pyramid
- Population ecology
- Types of breeding in animals
- Biopesticides /Biofertilizers
- Application of biotechnology
- Codominance and incomplete dominance in genetics
- Monohybrid / dihybrid cross (very important from examination point of view)
Below is the example of questions:


- Motivation
Motivation is the most important factor. If you are motivated enough and have that urge to perform then you will definitely be able to do it. The motivation to study and practice regularly before the exam and then continuously write for 3 hours on the exam needs a high level of motivation. Remember that this one exam can have a great impact on satisfying the qualifying criteria of competitive exams.
Next time, I’ll be back will important tricks of other subjects as well. Until then this is me Abhishek saying BYE!